Représentativité Statistique des AB tests : Bayésiennes ou Fréquentistes
L’AB testing permet aux marketeurs d’exploiter la puissance des données afin de déterminer quelle version d’une page web est celle qui convertit le plus de visiteurs en acheteurs. Cependant, avant de procéder à la refonte complète d’un site web, plusieurs décisions cruciales basées sur les statistiques doivent être prises pour un calcul et une interprétation correcte des résultats : Et l’une d’elle est le calcul de la représentativité statistique (Statistical Significance en anglais).
Sommaire :
- Approches sur la Représentativité Statistique : Bayésiennes ou Fréquentistes
- Comment choisir l’approche qui me convient le mieux ?
- En quoi consiste l’Approche Hybride et comment peut-elle vous aider dans vos tests ?
- AB Testing : Bases statistiques & Définitions
- En savoir plus sur la représentativité statistique et l’Approche Hybride
Afin d’assurer le succès de vos AB tests, il est impératif que les données soient correctement collectées et analysées et que les informations obtenues soient ensuite parfaitement comprises.
Si les résultats sont interprétés de manière incorrecte, vous courez le risque de mettre en œuvre une variation de votre site web qui n’a pas prouvé mathématiquement qu’elle pouvait augmenter les ventes ou le nombre de prospects. Vous risquez même de diminuer les conversions.
Même si l’analyse des résultats de vos tests peut sembler une tâche objective, il existe en réalité un certain nombre d’avis sur la manière de collecter vos données.
[sta_anchor id= »bayesiennes-vs-frequentiste »]Approches sur la Représentativité Statistique : Bayésiennes ou Fréquentistes[/sta_anchor]
L’approche Fréquentiste
L’approche Fréquentiste est utilisée lorsque seules les données brutes, recueillies pendant une expérience, sont utilisées pour établir des prévisions.
Supposons que vous souhaitiez savoir quelle page web, A ou B, fonctionne le mieux au cours d’un jour en particulier, comme un Lundi par exemple. À la fin de ce Lundi, vous prenez les données de la journée, vous calculez la représentativité statistique (Statistical Significance) d’un pic de conversions pour votre page B et déterminez que la page B a effectivement mieux fonctionné que la page A.
L’approche Bayésienne
L’approche Bayésienne est utilisée lorsque des données et des résultats antérieurs sont pris en compte en plus des données brutes de l’expérience actuelle afin de tirer des conclusions.
Utiliser cette approche à la même expérience, mentionnée ci-dessus, impliquerait de prendre en compte le trafic et les données de conversion des dix Lundis précédents ainsi que du Lundi en cours lors de l’expérience.
[sta_anchor id= »quelle-approche-choisir »]Comment choisir l’approche qui me convient le mieux ?[/sta_anchor]
Les deux approches ont leurs avantages et leurs inconvénients. L’approche Fréquentiste, ou «classique», est plus rapide et moins complexe, car elle utilise des calculs statistiques simples et un ensemble de données fixes qui sont uniquement liées à l’expérience en cours. Cependant, cet ensemble de données, bien que limitées, sous-entend qu’il y a plus de chances que les résultats soient simplement dus au hasard.
L’approche Bayésienne est plus complexe, mais aussi potentiellement plus fiable. Elle repose sur l’hypothèse que si un certain résultat a déjà été observé, il y a de fortes chances que cela se reproduise à l’avenir.
Pour les férus de philosophie, la probabilité Bayésienne – inventée au XVIIIe siècle par le ministre presbytérien Thomas Bayes – aurait apparemment été élaborée pour contrer l’argument de David Hume selon lequel un événement « miraculeux » était peu susceptible d’être véritablement « miraculeux » en raison de l’extrême rareté d’un miracle.
Bayes a potentiellement cherché à défier Hume en montrant que les résultats futurs pouvaient être prédits mathématiquement par les circonstances passées, plutôt que par la rareté d’un résultat.
Comme le notait un article du New York Times de 2014, même Hume lui-même aurait été «impressionné» s’il avait vu que, en 2013, les garde-côtes de New York ont utilisé des statistiques Bayésiennes pour localiser et sauver un pêcheur tombé à l’eau dans l’océan Atlantique.
Alors… Quelle approche devrais-je utiliser ? L’approche Fréquentiste ou Bayésienne ?
Les AB tests nous ont permis d’analyser statistiquement plus de points de données sur une période plus courte – ce qu’on appelle l’approche Fréquentiste.
Mais cela nous empêche potentiellement d’obtenir les résultats les plus précis possibles. Si nous analysons les résultats d’un coup d’oeil trop rapide et constatons que la représentativité statistique a été atteinte, nous risquons d’arrêter l’expérience avant qu’elle ne soit réellement terminée, à cause d’une erreur.
Cependant, l’AB Testing nous permet également d’introduire et d’appliquer avec précision des algorithmes statistiques plus complexes prenant en compte les résultats passés – ce qu’on appelle l’Approche Bayésienne. Cependant, prendre en compte les résultats passés est plus compliqué et prend plus de temps. Il se peut qu’on ignore de nouvelles données au profit d’informations obsolètes.
La meilleure approche en matière de Statistical Significance pour vos AB tests consiste donc à utiliser le meilleur des deux approches dans ce que nous appelons chez Convertize l’Approche Hybride.
[sta_anchor id= »approche-hybride »]En quoi consiste l’Approche Hybride et comment peut-elle vous aider dans vos tests ?[/sta_anchor]

Habituellement, le niveau de représentativité statistique en AB Testing est calculé en utilisant une taille d’échantillon fixe, attribuée à l’approche Fréquentiste, car en réduisant la taille de l’échantillon vous obtenez des résultats plus rapidement.
Ce désir de résultats rapides peut amener les marketeurs à calculer et à vérifier la représentativité à la fin de chaque jour d’une expérience est en cours. De nombreux statisticiens préconisent une règle du «pas de coup d’oeil»! En effet la plupart des marketeurs pourraient être tentés de mettre fin à une expérience dès lors que la représentativité statistique est obtenue, avant même que la taille requise de l’échantillon n’ait été atteinte.
Cette règle du «pas de coup d’oeil» est due à un phénomène statistique appelé «régression vers la moyenne».
Cela signifie que si vous mesurez un pic de données, la mesure suivante sera plus proche de la moyenne. Une régression vers la moyenne peut se produire dans vos mesures en raison d’une erreur d’échantillonnage, telle qu’un échantillon trop petit et par conséquent non représentatif de la population choisie.
Si vous jetez un coup d’œil aux résultats de vos AB tests avant que la taille requise de l’échantillon n’ait été atteinte et que les résultats ne sont pas représentatifs de la population réelle en raison d’une régression vers la moyenne, vous aboutirez à des conclusions incorrectes.
Étant donné que les taux de conversion, la taille des échantillons d’un test AB et, par conséquent, tous les paramètres d’un AB test évoluent continuellement au cours d’une expérience, nous avons décidé de calculer le niveau de représentativité à partir d’un certain nombre de jours définis après le début d’un AB test, puis ensuite tous les jours jusqu’à la fin du test, afin de donner à nos clients des résultats robustes et fiables.
Notre algorithme calcule le niveau de représentativité statistique seulement après un certain nombre de jours et non dès le début d’une expérience, en raison de la volatilité des données collectées au début des tests, et ce à cause du problème de la régression vers la moyenne et d’autres erreurs. Après ces premiers jours d’attente, nous calculons et fournissons le niveau de représentativité à la fin de chaque journée du test.
OK, j’ai compris – Comment utiliser l’Approche Hybride pour calculer la Statistical Significance ?
Afin d’utiliser l’Approche Hybride avec succès, il est important de bien comprendre les outils statistiques utilisés pour calculer les résultats de vos AB tests.
Dans la section suivante «AB Testing : Bases statistiques & Définitions» nous allons détailler les bases de la représentativité statistique et nous aborderons les calculs plus complexes sur comment calculer la représentativité statistique de vos AB tests en utilisant l’Approche Hybride.
Si vous êtes un professionnel chevronné dans ce domaine, passez à la section suivante !
Si vous pensez avoir besoin d’un petit rappel, je vous conseille de lire cette section…
[sta_anchor id= »statistiques-ab-testing »]AB Testing : Bases statistiques & Définitions[/sta_anchor]
Qu’est ce que la représentativité statistique (ou Statistical Significance) ?
En AB Testing, le calcul le plus important afin d’interpréter les résultats de vos tests est la représentativité statistique, c’est-à-dire la probabilité que la différence entre les taux de conversion de deux variations d’une page web résulte de réels changements dans le comportement des consommateurs. C’est un moyen statistiquement solide de prouver que vos résultats sont fiables avant même de tirer des conclusions.
Les marketeurs et les testeurs web attendent un certain niveau de représentativité avant de définir la variation gagnante. C’est le moyen le plus simple de vous assurer que vous êtes certain d’avoir des résultats significatifs lorsque vous analysez les données de vos AB tests.
Le niveau de représentativité statistique le plus généralement utilisé est établi à 95%. Cela signifie que 19 fois sur 20, la variation que nous avons choisie comme gagnante est LA vraie gagnante. La probabilité que les résultats ne soient pas fiables et donc simplement dus au hasard, est de 1/20.
Si votre AB test révèle que vos résultats sont statistiquement significatifs avec un taux de p <0,05, la probabilité que cela soit de la chance est inférieure à 95% – ce qui veut dire que 19 fois sur 20 lorsqu’un visiteur a finalisé une vente, c’est sur la version “B” de votre site plutôt que sur la version “A”.
De même, cela signifie que dans 95% des cas, nos résultats ne sont pas dus au hasard.
Qu’est ce que la “taille de l’échantillon » ?

En statistiques, la taille d’échantillon est un terme important qui fait référence au nombre de visiteurs « utilisés » pour collecter des données dans une expérience. Dans le cas d’un AB test, il s’agit du nombre de personnes ayant visité les deux variantes d’une page web.
En général, plus la taille de l’échantillon est grande, plus le test sera précis.
Le vrai danger avec un volume de visiteurs testées trop petits est qu’une «anomalie», ou plutôt une donnée dont la valeur diffère grandement du reste des résultats aura un impact important sur les résultats interprétés, et donc sur les prévisions. Il y a donc un risque concernant la fiabilité de vos AB tests.
Qu’est-ce que « la moyenne » ?
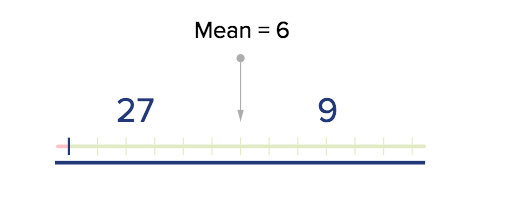
La moyenne signifie tout simplement «la moyenne». En AB Testing, nous mesurons le taux de conversion moyen pour chaque variation.
Qu’est ce que la Variance et l’Écart type ?
Variance – la différence entre nos résultats et nos attentes
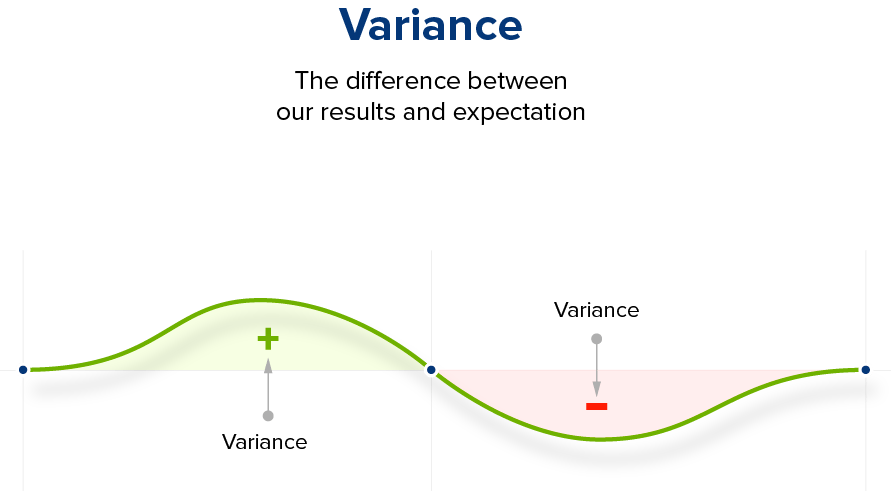
La variance mesure l’écart moyen entre les nombres d’un ensemble de données. Il mesure l’écart entre chaque nombre et la moyenne. Habituellement, nous visons à minimiser la variance. Plus la variance est petite, plus la moyenne reflètera correctement le taux de conversion typique d’une variation.
L’écart-type exprime la façon dont les données sont regroupées autour de la moyenne. Plus l’écart type est faible, plus l’ensemble de nos données est proche de la moyenne.
Qu’en est-il de l’hypothèse ?
Avant de pouvoir prouver qu’une hypothèse, ou en d’autres termes, une supposition éclairée est vraie ou fausse, nous avons besoin de toutes les données afin d’établir cette conclusion. Nous devrions donc examiner de près la ‘population’ de l’ensemble de nos données. En AB Testing, notre hypothèse est que la page B que nous optimisons en utilisant des notifications de nudge marketing, en modifiant les appels à actions, en ajoutant des avis clients, etc. fonctionnera mieux que la page actuelle, qu’est la page A.
Ok, vous avez tout compris ? Parfait. Il est maintenant temps de commencer à tester.
Testez votre hypothèse
En statistique, nous utilisons «l’hypothèse de test» pour tirer des échantillons aléatoires de la population. Cela nous permet de décider si notre hypothèse est vraie ou fausse, et nous permet d’éviter de conclure que des résultats soient dûs à la chance.
Pour ce faire, nous devons d’abord comparer notre hypothèse éclairée – H1, «l’hypothèse alternative» – à H0, «l’hypothèse nulle».
Une hypothèse nulle indique qu’il n’y a pas de changement dans les données entre les deux populations d’une même expérience – par ex : Les pages web A et B dans un AB test ont montré exactement les mêmes taux de conversion.
H1 est un résultat alternatif à H0, qui ne représente aucun changement dans les populations malgré les conditions expérimentales.
H0 = l’hypothèse nulle
H1 = l’hypothèse alternative
Ce que nous voulons tester, c’est de savoir si H1 est vraie.
Dans ce cas, 2 résultats sont possibles :
1.Nous rejetons H0 et acceptons donc H1 car nous disposons de suffisamment de preuves à l’appui.
2.Nous ne pouvons pas rejeter H0 car nous n’avons pas suffisamment de preuves.
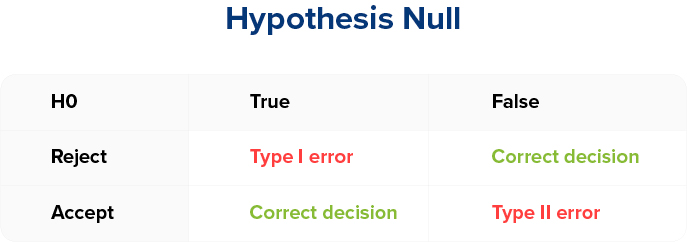
Le rejet de H0 même lorsque H0 est vrai est appelé une erreur de Type I.
Commettre cette erreur signifie qu’en interprétant les résultats, nous avons conclu qu’il y a eu un changement dans les taux de conversion entre les pages web A et B pendant les tests, même si les données révèlent qu’il n’y a pas eu de changement.
La probabilité de NE PAS commettre cette erreur est appelée le «niveau de représentativité statistique», dans la langue des spécialistes du marketing.
En statistique, nous définissons H0 afin de le relier à ce type d’erreur. L’erreur de Type I est généralement l’erreur que nous souhaitons le plus éviter car il est plus important de ne pas commettre d’erreur de Type I que de commettre une erreur de Type II.
En effet, commettre une erreur de Type I signifierait observer un changement d’une variation par rapport à une autre alors qu’il n’y a en fait aucun changement du taux de conversion entre les deux variations. Par conséquent, un marketeur risque de mettre en oeuvre accidentellement des modifications perçues comme augmentant les ventes alors qu’il n’existe aucune preuve du bénéfice.
L’acceptation de H0 lorsque H0 est faux est une erreur de Type II. La probabilité de NE PAS commettre cette erreur s’appelle le «puissance».
Relation entre les taux d’erreur des Types 1 et 2 :
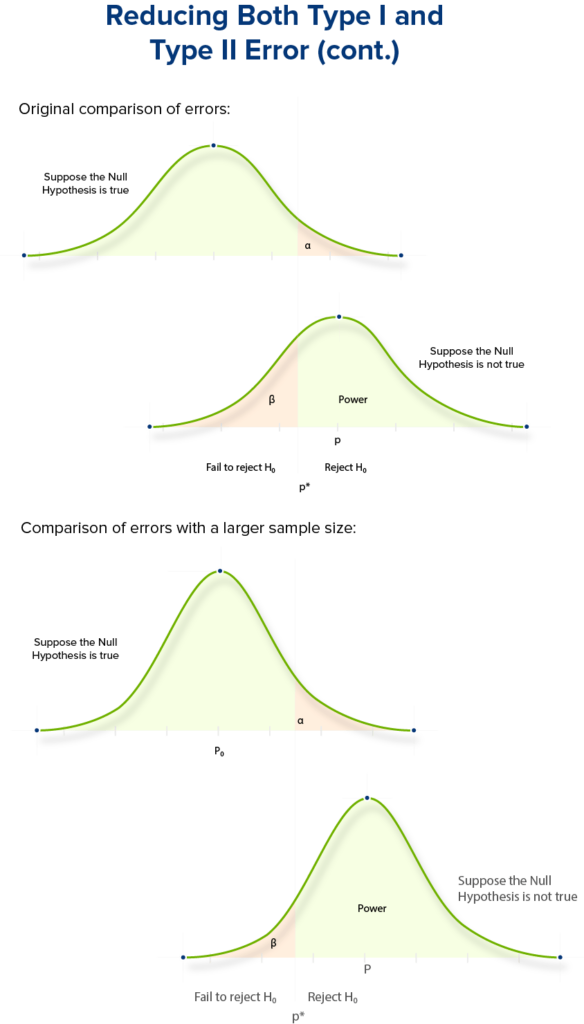
Il est important de noter que ces deux erreurs sont antagonistes : nous ne pouvons pas essayer de réduire les erreurs de Type I et de Type II en même temps.
Comme vous pouvez le constater sur les deux courbes en cloche, essayer de réduire l’une des zones d’erreur en déplaçant “N’importe quelle moyenne” entraînera directement une augmentation de l’autre type d’erreur.
Cependant, nous pouvons simultanément réduire la probabilité de commettre l’une ou l’autre de ces deux erreurs en augmentant la taille de notre échantillon – dans ce cas, le nombre de visiteurs des pages web A et B.
[sta_anchor id= »ab-testing-whitepaper »]En savoir plus sur la représentativité statistique et l’Approche Hybride[/sta_anchor]
Pour lire l’article complet sur l’Approche Hybride et sur la manière dont elle résout le problème de la représentativité statistique en AB Testing, je vous invite à télécharger notre Livre Blanc gratuit en anglais.
PS : Cet article a été rédigé avec la collaboration de Yanis Tazi.
Si vous n’avez pas encore de logiciel de A/B testing et vous ne savez pas comment choisir, vous pouvez consulter les 10 étapes pour choisir le meilleur outil d’AB testing. Notre comparatif de 26 logiciels d’AB testing pourra vous aider dans votre recherche.
Par Philippe Aimé
Philippe est Directeur chez Convertize. Philippe a créé son premier site Internet en 1998. Il dirige aujourd'hui l'équipe de consultants en Optimisation des Conversions.
